The new (v6+) Attribute Browser view lets you review all the unique values for a selected attribute and see which notes use that attribute value. But, what if you want to know the number of unique values and to make a note for each such value? This short tutorial shows how to do that.
The technique is generic to all sorts of of subjects. Here the context used is that of cataloguing characters in the plot of a novel; their names are stored in a Set-type user attribute $CharacterSet. The latter holds the names of one or more characters in the story who appear in a given scene.
Note that the technique works with both multi-value (Set, List) and single-value attributes (String, Number, etc.).
Where example attribute names like $MySet or $MyString are given, this is to indicate the attribute data type you should expect to use. Of course, you can substitute more meaningful attribute names in you own projects. If copying code, simple change the specimen attribute names to match your own attribute names.
This document was last revised using Tinderbox v7.5.4 on macOS 10.13.6.
Author: Mark Anderson (a Tinderbox user since 2004).
1. Collect values for the whole document
The values() operator returns a Set, i.e. a list of unique values, for a specified attribute. That attribute is passed (without a $-prefix) as a values() parameter:
$MySet = values("CharacterSet");It is often the case, especially for user attributes, that only the notes of interest will have values for the desired attribute. Thus, using values() will suffice to get the desired list (without any unwanted extra values).

2. Collecting the values for part of a document
However, you may need to collect values from a more narrow context. For instance, only scenes for Chapter 1, or only those scenes in Chapter 1 that take place in 'Molvania'. The approach varies slightly for v6 and v7, owing to the changes to values() and in how collect() handles list values.
2.1 v7 only: Using scoped values()
The values() operator returns a Set, i.e. a list of unique values, for a specified attribute. That attribute is passed (without a $-prefix) as a values() parameter. In v7+, there is an optional first parameter that controls the scope of the values returned. If omitted, the scope is whole-document.
To collect only characters from scenes in Chapter 1 (which we'll assume are child notes of 'Chapter 1'):
$MySet = values(find(inside("Chapter 1")),"CharacterSet");To return characters only from scenes in Chapter 1 that take place in the country of 'Molvania '(as stored in user attribute $SceneCountry):
$MySet = values(find(inside("Chapter 1")& $SceneCountry=="Molvania"),"CharacterSet");Tip: If either or both of the group of notes to test or the 'if' condition are complex, you might want to consider first adding a user attribute tio the target notes to make them easier to specify in queries/conditional tests.
2.2 v6 only: Using collect() and collect_if()
To obtain values at less than document-scope, it is necessary to use either collect() or collect_if(). These both return a List [sic] so you will definitely need pass the return values to a Set which will result in a de-duped list of unique values.
To collect only characters from scenes in Chapter 1 (which we'll assume are child notes of 'Chapter 1'):
$MySet = collect(find(inside("Chapter 1")),$CharacterSet);To return characters only from scenes in Chapter 1 that take place in the country of 'Molvania '(as stored in user attribute $SceneCountry):
$MySet = collect_if(find(inside("Chapter 1")),$SceneCountry=="Molvania",$CharacterSet);Tip: If either or both of the group of notes to test or the 'if' condition are complex, you might want to consider first adding a user attribute tio the target notes to make them easier to specify in queries/conditional tests.
3. Where to store the value list
It is a good idea to make a new note that will become the container for your new list of values, in this case the list of characters. Where in the TBX document the note goes doesn't really matter, but it will likely reflect the degree of structure in your document. For instance, you may make a new container to house discrete containers for characters, locations, etc., each being produced by separate iterations of this technique with different source attributes. Bottom line: use as little or as much structure as your project demands.
For the sake of this exercise, and so we can refer back to it below, this exercise will use a new note with the (unique) $Name of "Character Listing".
4. Counting the values
This is actually quite simple and can be obtained from the list created in the previous steps, stored in $MySet, using the .size operator. The latter returns Number-type data:
$MyNumber = $MySet.size;So, if $MySet has 24 discrete list items, $MyNumber's value will be 24. By setting MyList as a key attribute in the note collecting values you can quickly get a feel for size of the dataset before going further. If it looks low (or high) you might want to check the previous steps.
5. Exploding the value list
The $MySet for "Character Listing" has a list of all the unique character names. The process of creating a note for each list item involves:
- storing the list as the note's
$Textwith one value per line - exploding the
$Text - [optional] applying a prototype to the new notes
- removing the "exploded notes"container
- [optional] sorting the new notes within the parent container
Tip: before starting this process, it may be useful to create a new prototype "Character" with appropriate key attributes, etc. The tutorial will assume this has happened.
5.1 Passing $MySet values to $Text
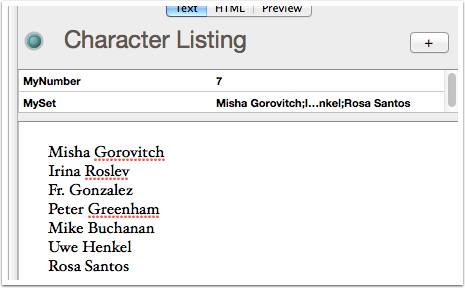
This is done in a simple rule for the "Character Listing" note:
$Text = $MySet.format("\n")The rule tells Tinderbox to reformat the list as a single string putting a line return character between each list item. The result is that $Text has a list of characters which each as a separate line/paragraph (the paragraph aspect is pertinent for the next step). Don't worry if the sorting is not as desired as this can be corrected later.
Before continuing, take a look at the $Text and scan the values for anything unexpected. If using collect()/collect_if() this will help spot missing/extra values. If errors are found, fix the $MySet data and let the rule run again. You may find it useful to add $MyNumber and $MySet as key attributes to assist with diagnostic efforts if you have problems.
5.2 Exploding $Text
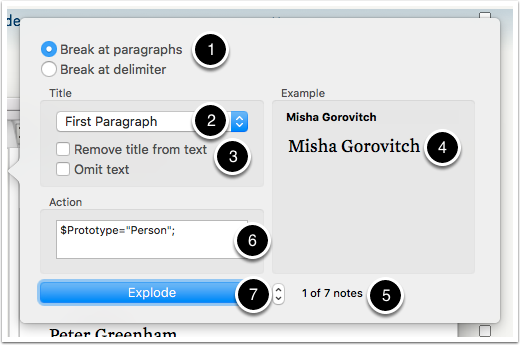
Next, the selected note's $Text is 'exploded' into discrete per-line notes. The Explode operation is called from the Note menu. Be aware the option is only available if focus is in the main pane and not in the text pane).
There a few things to note on the Explode pop-over:
- Use the default radio button selection 'Break at paragraphs', i.e. at each hard line-break in the source
$Text. (but, see notes blow) - Choose the non-default value of 'First Paragraph' from the pop-up list. The default choice is 'First Sentence' such as might cause a source value like 'Fr. Gonzalez' to make a note titled 'Fr', which is not what you want.
- Tick the box to 'Omit text'. Otherwise the character name will be used as both the new note title and as its $Text. Of coure, if that's what you want, leave the box un-ticked.
- This pane shows the title and text (if any) of for the new note to be created from the first source paragraph. It can help with checking you've selected the right choice of settings.
- This shows the number of new notes to be created.
- (v7+ only). An optional action can be set, which is functional equivalent to a container's OnAdd action.
- When ready, click the Explode button.
Notes:
- Tip: the number at #5 above should match the source note's
$MyNumber. If not, re-check your settings. - Settings made on this dialog are retained (for the current document) making it easy to repeat the same task
- Whilst breaking a paragraphs is sensible tasks, for many tasks such a importing data formatted in/exported from other apps the use of a custom delimiter is often the better/necessary choice.
5.3 Explode Result
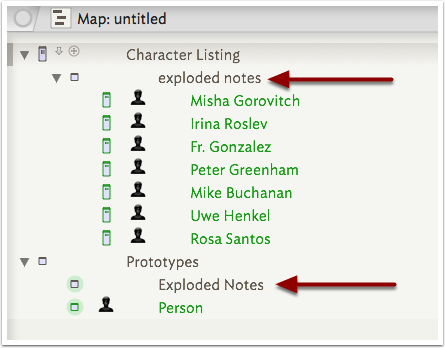
Note: in v6, no prototype is applied (see optional step below)
The result of the Explode is a new child container called 'exploded notes'. This name is used for every Explode result, which can be useful if you work involves using this process regularly as it makes it easy to look for such containers and work on their content, e.g. to move them elsewhere, apply attribute values. The container has a key attribute of $ChildCount which helps check the result of the explode when using large datasets.
The other result (v7+ only) is to add a new prototype 'Exploded notes' (note capitalisation difference from container name). By configuring this prototype it can remove the need to use the optional action in the Explode step. From v7.5.0+, this built-in prototype can be added manually before the document's first Explode task. This makes it easier to pre-configure an import process that makes use of the prototype; prior to this you had to do an Explode just to create the prototype.
5.4 (v6.x only)Optionally set a prototype for the new notes
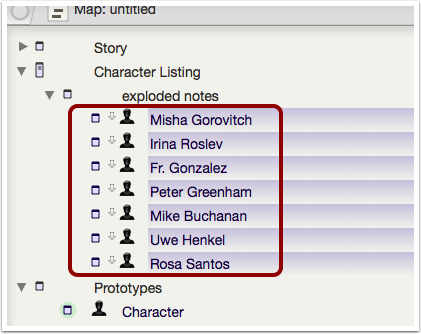
At this point, if you have made a prototype, e.g. here called 'Character', select the new exploded notes and apply the prototype. You can do this either via the Inspector or by right-clicking the icon of any of the selected notes and selecting the desired prototypes from a pop-up list.
5.5 Remove the 'exploded notes' container
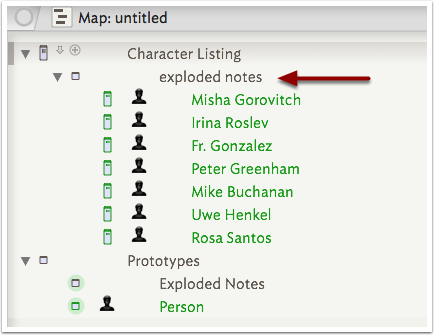
Select all the new notes and then press Shift+Tab to promote them out of 'exploded notes'. Then select and delete 'exploded notes'.
5.6 Sorting - 1
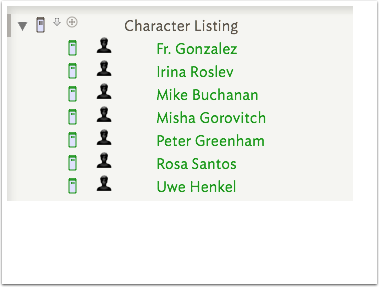
The original post-explode sort order had no particular logic. Setting a new sort ($Sort) to the 'Character Listing' to use note title ($Name) doesn't help much either - as shown here - because the first names are influencing the sort order.
5.7 Sorting - 2
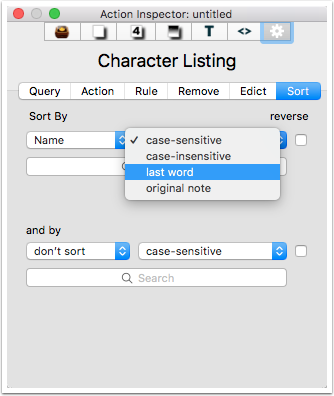
On the sort inspector, the right-hand pop-up (which sets $SortTransform) has a useful option 'last word', which takes the last word of the nominated sort attribute's value.
5.8 Sorting - 3
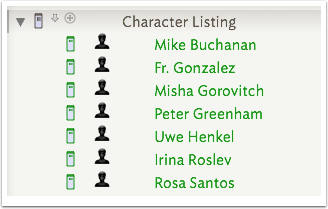
The 'last word' transform gives a better result. For more simple string values there are usually fewer issues relating to sorting. However, if you have a mix of source values starting with uppercase and lowercase letters, the 'case insensitive' sort transform is probably more useful than the default.
5.9 Sorting - 4
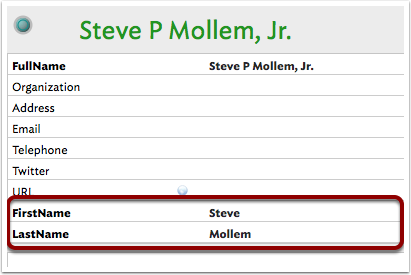
If you have more complex character names like 'Henry Wultz III' or 'Steve P Mollem, Jr.', it might be useful to add new custom String-type attributes $FirstName and $LastName to assist specifically with sorting (or use something like $SortName for the (last) name on which to sort). Either add these to the notes, or more likely to the prototype they use.
For the above example, these might hold the values 'Steve' and 'Mollem' to assits more precise sorting. Again, this sort of sort intricacy is most common with people's names. Generally, just sorting on $Name will suffice for an alphabetical list.
6. Task complete
You now have a set of per-list-value notes which can be used as needed. In this case, the notes might be used to hold biographic notes about the characters in the $Text and perhaps add more information in additional user attributes. Again, using a prototype makes it easy to add new attributes as a key attribute to all the character notes at once.
Extra attributes might hold the character's nationality, age, and other such factors you might want to be able to query (e.g. 'are any of the Molvanian male characters over 60 years old?', etc).
7. Efficiency
Generally, you will want to do this process once only per source data, or perhaps a few times. As such, there is little gain in leaving the rules or agents that create $MySet and parse to $Text to run all the time. This is especially true as documents grow and more rules get added. Use $RuleDisabled or $AgentPriority to switch off action code when not needed.
8. Linking to source values
Quite often, having extracted the values it is useful to link these per-value notes to the note(s) where they are used. If you simply wish to view that association, don't overlook Attribute Browser view within Tinderbox. But, if wish to use these relations hips for other task, such as to export to other tools, it can be useful to create Tinderbox links.
Assume you've collected the values of of the author names of all authors (there may be more than one per paper) in a set of references. Now, you want to make each discrete author link to each reference where she is an author (as defined in $Authors). Assume also that you've set all 'author' notes to use a prototype 'Author'. Rather than set code per-author, you can now simply use the prototype. It might seem intuitive to use a rule, but now each author note is constantly checking the document for new possible links. Better is to set and edict in the prototype. this will run once when set and likely finish the task. If so the edict can be deleted.
8.1 An Edict to link to sources
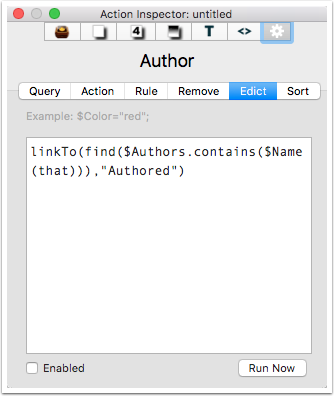
In this case, author notes using the prototype 'Author' will link from the note to any reference(s) using the link type 'Authored'.
9. Dealing with changes
Depending on your source material, the list of original values may change. It is not possible to auto-update the exploded lists, but there are simple ways to deal with such scenarios. If you make your listing note show both $MyNumber and $ChildCount, the two should match as long as there is no change in the source values. This assumes you've refreshed $MySet from source (i.e. re-run your rule).
9.1 Additions
As you have likely done some customisation of the original exploded notes, it is probably best to add new items manually as new notes. If the list is big, to detect the new values copy $MySet to $MyList in a new note. In the latter sort the list as per the existing per-character notes and then put the list into the new note's $Text. The new list can then be cross-read against the existing notes and anything missing can be manually inserted/configured.
9.2 Deletions
As above, but use the secondary list to find and delete notes for characters you've discarded.
10. Summary
This tutorial has shown a simple method to pull attribute-derived lists into actual notes named as per the list item. Although the example uses characters in a story, the listing source could be attributes for tags, topics, projects, papers' authors, etc. The same principles apply.
Once you have these per-item notes it is possible to then do things like get counts of notes using that value, or to automatically create links to or from such notes. That is a task that will be used for a separate tutorial.